Metadata
Metadata is "data about data".
Metadata is used to store information about data assets that are stored in the GBADs knowledge engine. We strive for metadata to be FAIR (Findable, Accessible, Interoperable, and Reusable).
In addition, we collect metadata on the processes in ingesting data into the Knowledge Engine to ensure that all data lineage is tracked.
Metadata Schema
"A metadata schema is a set of rules about what sorts of subject-predicate-object statements one is allowed to make, and how one is allowed to make them." - Jeffery Pomerantz
A subject-predicate-object statement consists of:
- Subject = the thing being described
- Object = the thing describing the subject
- Predicate = relationship between the subject and object
For example:
- Subject = FAOSTAT QCL dataset
- Object = FAO
- Predicate = creator
In this subject-predicate-object statement the FAO is the creator of the FAOSTAT QCL dataset.
Based on this model, we can craete a metadata schema that defines the predicates (also called elements) that we would like to use to describe a resource. Metadata vocabularies such as Dublin Core, schema.org, PROV-DM, and DCAT , provide metadata elements that can be used to describe data. There is not a 'one-size-fits-all' when it comes to metadata. Several standard metadata element sets exist because what you will include in metadata depends on what your use case is.
We have selected metadata elements from schema.org and PROV-DM to describe data and trace data lineage in the knowledge engine (see Figure below).
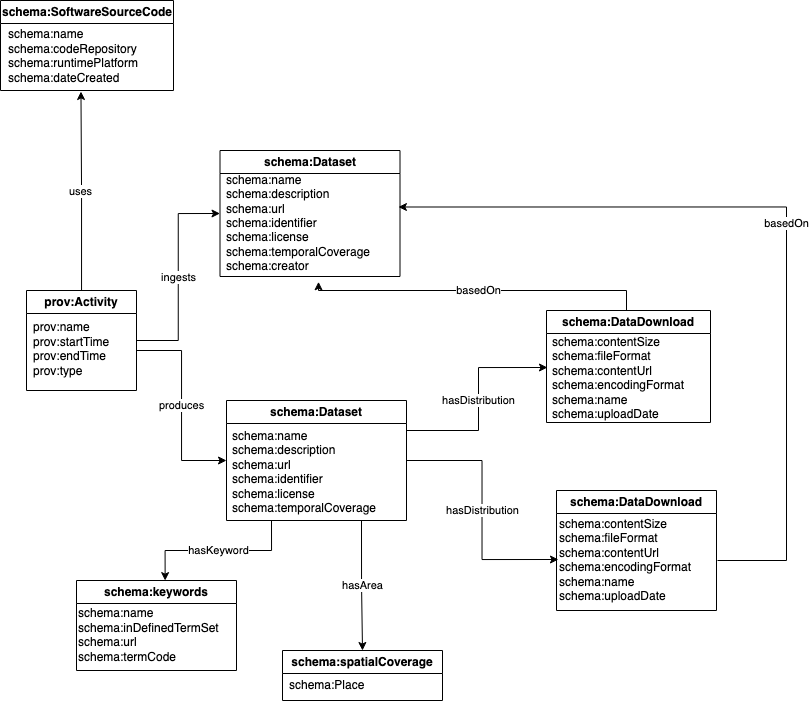
Encoding Schema
Each metadata element should have instructions on the expected values expected for each element. For example, there are many different ways to specify a date: 01/04/23 could mean January 4th, 2023 or April 1st, 2023. Therefore, any values for any element specifying a date should use ISO-8601 to ensure that all dates are formatted in a standard fashion.
The encoding schema for each metadata element used in the metadataModel is found below:
| Element | Encoding Scheme | Expected Type |
|---|---|---|
| name | free text | str |
| codeRepository | link to GitHub repo | str |
| runtimePlatform | name of programming language or platform used at runtime (need controlled vocabulary) | str |
| dateCreated | ISO-8601 | datetime |
| startTime | ISO-8601 | datetime |
| endTime | ISO-8601 | datetime |
| prov:type | Controlled vocabulary to be built for use case (i.e ingestionEvent, dataCleaning etc.) | str |
| description | free text | str |
| url | url | str |
| identifier | url, doi, or uri | str |
| license | url | str |
| temporalCoverage | ISO-8601 | datetime |
| creator | free text | str |
| inDefinedTermSet | url | str |
| termCode | code from defined term set | str |
| Place | GeoNames | str |
| contentSize | File size in megabytes | float |
| fileFormat | File format. One of: csv, json, dbtable etc. (controlled vocabulary required) | str |
| contentUrl | url | url |
| uploadDate | ISO-8601 | datetime |
Decision needed:
Currently, keywords for metadata are created through extracting terms (like species), from data sets.
A controlled vocabulary needs to be created to link keywords to. We have begun to do this by collecting all species classifications and definitions from data sources, however, synonyms have not yet been identified.
Vocabularies and Ontologies
Pre-existing vocabularies and ontologies will be accessed, refined, compared and extended upon to create a controlled vocabulary for GBADs. Semantics will be accessed for each data source to ensure that the words used to describe data are consistent between data sources.
- Vocabularies for data sources that don’t cite vocabulary standards will be obtained and words will be compared to pre-existing data standards such as AGROVOC (FAO’s controlled vocabulary)
- Collected vocabularies will be compared for all data sources, to see how the description of terms compares to each other.
- Goal is to provide a standard for GBADs, increasing interoperability and quality of data, ultimately leading to
superior models and estimates
- Also controlled vocabularies lead to better systems and allow for automation of tasks
Agroportal is an ontology mapping tool that will allow GBADs to determine suitable ontologies and mapping between standardized vocabularies related to the agricultural sector.
- We also acknowledge that we cannot expect data contributors to change their vocabularies to follow that of GBADs (and if we did ask, it may discourage people from contributing data). This underlines the importance of vocabulary mappings.
Metadata Storage and Management
"All the knowledge is in connections"
GBADs Informatics uses neo4j, a graph database management system, to manage and storage metadata and information about individuals and groups involved in the project. As you will learn in this section, a graph database is a type of database that leverages the idea of connections between entites as a method to derive insights and new knowledge from otherwise disconnected data.
What is a graph database?
A graph database is a type of database that stores data using relationships between main ideas or entities. The relationships between different entities show connectedness, allowing for more insights to be drawn than a traditional relational database. Because data is highly complex and multidimensional in terms of structure, provenance, governance, security and semantics, GBADs uses graph databases for master metadata management and data cataloguing. By leveraging the dynamic nature of the graph database and structuring our graph model in a way that enables improved understanding of the many dimensions of data, we can both visualize and understand how data flows outside and inside our organization. Graph databases also allow us to add and change the structure as the structure of the information about data changes. This will become more clear as we introduce the preliminary GBADs graph data model.
Traditionally, data are organized into a series of tables. Each of the tables have columns, and some tables have common columns. With these common columns you can specify joins between tables, resulting in a new table.
The biggest advantage of relational databases is the ability to join common tables to derive insights. On the other hand, relational databases require rigid schemas which require database engineers to structure their data to fit the schema. This comes with the assumption that we know what all of our data already looks like, which isn't always the case for research.
Parts of a graph database
Graph databases are made up of nodes (entities) and edges (relationships). Nodes can have properties and labels while edges serve as the connection, or relationship between nodes.
A graph model is a model of what kinds of nodes you are representing and how they are connected (what relationships you will have).
 d
d
Graph Database and Metadata API
To be updated when API is launched