Accessing Data in the Knowledge Engine
Objectives:
- Understand how to access different types of data in the Knowledge Engine
- Understand how to search for data stored in the Knowledge Engine
For information about what to do when you identify new data sets of interest for use in the GBADs program visit the Data Contributor section of the Data Governance Handbook which outlines the following:
- Understand the roles and responsibilities of individuals who have identified a new data set for the use of GBADs program, and how to get this data stored in the Knowledge Engine
- Understand how Informatics stores data from models in the Knowledge Engine
The ways to access data consider the findability, accessibility, interoperability, and reusability of data for both humans and machines.
Data types in the Knowledge Engine
The data user guide provides GBADs collaborators with an overview of how to access data in the knowledge engine. We have 3 main types of data:
- Input data (or raw data)
- Output data from models
- Intermediate data sets
Each type of data and their subsets are uniquely formatted and require specific storage requirements to ensure that the data can be findable, accessible, interoperable and reusable (FAIR); all data must be documented with metadata to ensure that the data is FAIR.
Input data
Input, or raw data can come in two forms across the GBADs program:
- Data sets from sources such as the Food and Agriculture Organization of the United Nations Statistical Database (FAOSTAT), the World Organization for Animal Health (WOAH), national statistics agencies, etc.
- Parameters obtained from meta-analyses from systematic reviews.
- Data sets produced from expert elicitation exercises.
These data are the inputs to the models and calculations that GBADs themes produce. Input data can come in different forms, use varying terminologies and standards for naming countries, species, or other classifications, and thus may have various interpretations of the meaning.
All themes and modellers should be using the same input data that has been cleaned only once to ensure that we are all using the same inputs to models. This ensures reproducibility and accuracy of data across the program.
Output data from models
When models or estimates are produced, they produce parameters and data sets that may be used in subsequent models or estimations. The output data from models and estimates therefore need to be stored in the Knowledge Engine alongside metadata to ensure that all users can understand how the data were populated and produced, including the model code and datasets that were used to populate this data.
Intermediate data sets
Intermediate data sets may be data that were produced through a stage in modelling or imputation but are not considered an end product. Intermediate data, however, may be used for other modelling processes and may be important to ensure that the data processes are reproducible.
Accessing data in the Knowledge Engine
There are 2 main ways to access the data in the Knowledge Engine:
- Through the Application Programming Interface (API)
- Direct download through a URL from an Amazon S3 Bucket
APIs
What is an API?
API stands for Application Programming Interface. It is a machine-to-machine way to ask a server for data, get the server retrieve and interpret the data and return it to your machine. APIs are everywhere; they allow applications to 'talk' to each other. For example, when you check the weather on a weather app, the app is using an API to grab the data and present it in a usable and interpretable fashion on your phone. APIs provide the most up-to-date data without having to store data on your own machine.
For more information about APIs and how to use them visit the GBADs API Tutorial.
Input and output data are stored in Amazon RDS tables. The current functionality of the API includes:
- Provides access to data contained in the public databases
- Provides a list of all tables contained in the public databases
- For a given table, provides names of all fields and data types of those fields
While there may be a learning curve for human users of the API, APIs are important for providing machine-to-machine access to data (ensuring interoperability (exchange of information) between systems).
Documentation about how to build API calls is available at the GBADs Data Portal Documentation Page.
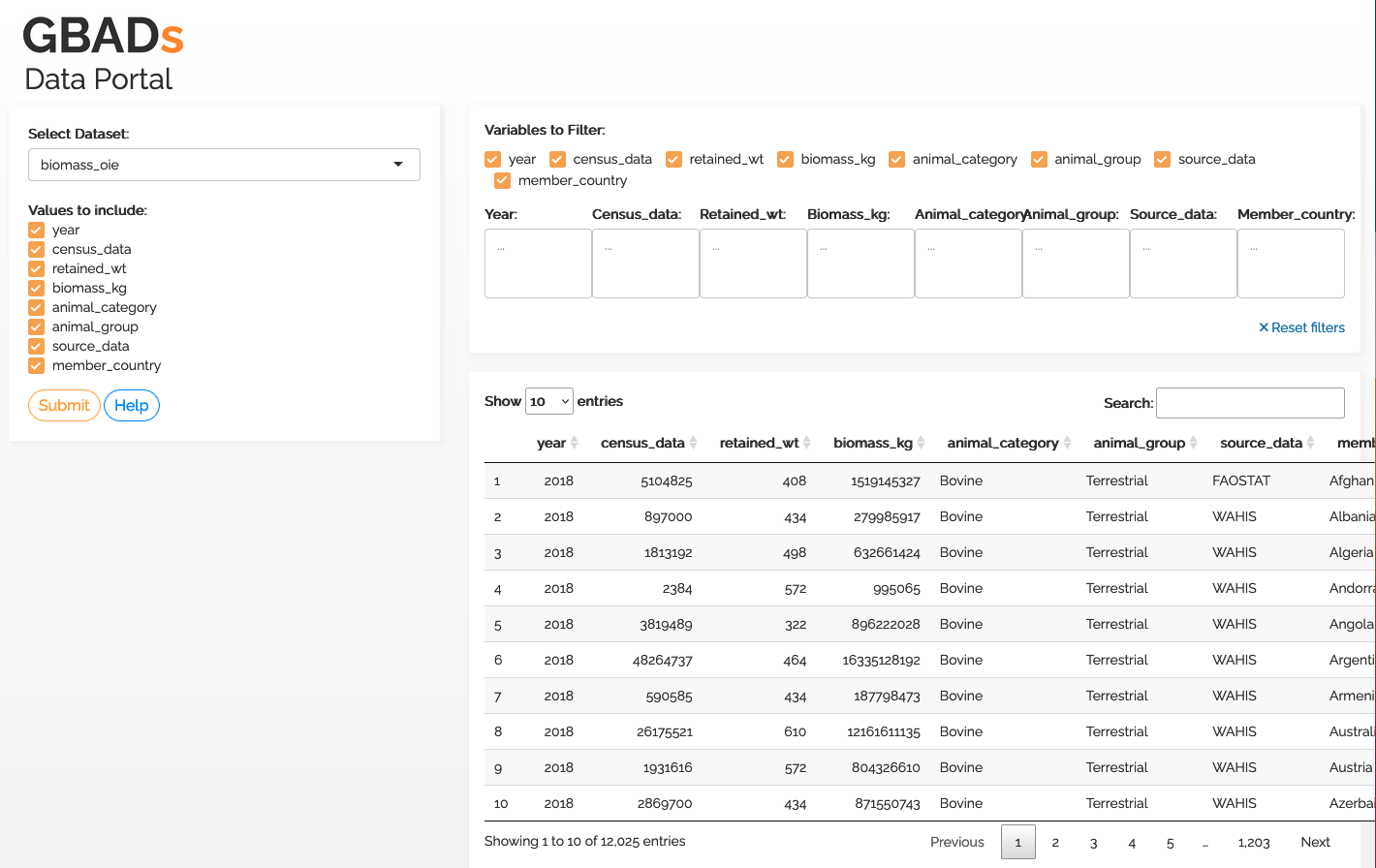
To improve the ease of use for human users, Kurtis Sobkowich created a dashboard to view and download data from the GBADs API. The URL will be linked in the Handbook when the dashboard is served on the GBADs server. For now, the dashboard is available on Kurtis' R shiny server: (GBADs API User Interface)[https://kurtissobkowich.shinyapps.io/GBADs_API_UI/]. Please expect delays - the dashboard will be slow until it is served on the GBADs' servers.
We have also developed a tutorial for using the GBADs API in R: Accessing the GBADs API in R
S3 Buckets
What is an Amazon S3 Bucket?
An Amazon Simple Storage Service (S3) Bucket is a cloud object storage service that allows you to store data and other digital objects in the cloud.
Data from the API is also available via Amazon S3 buckets. Using the S3 URL, users can download csv versions of the data. In addition, we will store files that are used by GBADs that cannot be stored in RDS tables such as shapefiles, images, intermediate data files produced by models, data from meta-analyses and any other data that cannot be structured into an RDs table.
The S3 URL will be used as a unique identifier for the data, and will be available in a dataset's metadata. The S3 URL will then be discoverable through the GBADs metadata API, and eventually the data catalogue user interface (coming soon).
Ethiopia CSA S3 Files:
GBADs Data Portal Interface
Searching for data in the Knowledge Engine
To use the data in the Knowledge Engine, you need to be able to find it. The search functionality of the data is built using a metadata pipeline.
Each type of data has unique metadata that describes it. For more information about the metadata please visit the Metadata section of the Handbook.
The metadata API will be published soon with information about how to discover data sources stored in the GBADs KE based on descriptive information that describes data