Acceso a datos en el motor de conocimiento
Objetivos:
- Comprender cómo acceder a diferentes tipos de datos en Knowledge Engine
- Comprender cómo buscar datos almacenados en Knowledge Engine
Para obtener información sobre qué hacer cuando identifica nuevos conjuntos de datos de interés para su uso en el programa GBAD, visite la sección Colaborador de datos del Manual de gobernanza de datos, que describe lo siguiente:
- Comprender las funciones y responsabilidades de las personas que han identificado un nuevo conjunto de datos para el uso del programa GBAD y cómo almacenar estos datos en Knowledge Engine.
- Comprender cómo la informática almacena datos de modelos en Knowledge Engine
Las formas de acceder a los datos consideran la capacidad de búsqueda, accesibilidad, interoperabilidad y reutilización de los datos tanto para humanos como para máquinas.
Tipos de datos en Knowledge Engine
La guía del usuario de datos proporciona a los colaboradores de GBAD una descripción general de cómo acceder a los datos en el motor de conocimiento. Tenemos 3 tipos principales de datos:
- Datos de entrada (o datos sin procesar)
- Datos de salida de modelos
- Conjuntos de datos intermedios
Cada tipo de datos y sus subconjuntos tienen un formato único y requieren requisitos de almacenamiento específicos para garantizar que los datos puedan ser encontrados, accesibles, interoperables y reutilizables (FAIR); todos los datos deben documentarse con metadatos para garantizar que sean JUSTOS.
Datos de entrada
Los datos de entrada o sin procesar pueden presentarse en dos formas en el programa GBADs:
- Conjuntos de datos de fuentes como la Base de datos estadísticos de la Organización de las Naciones Unidas para la Alimentación y la Agricultura (FAOSTAT), la Organización Mundial de Sanidad Animal (WOAH), agencias nacionales de estadística, etc. *Parámetros obtenidos de metanálisis de revisiones sistemáticas.
- Conjuntos de datos producidos a partir de ejercicios de obtención de expertos.
Estos datos son las entradas a los modelos y cálculos que producen los temas de GBAD. Los datos de entrada pueden presentarse en diferentes formas, utilizar diferentes terminologías y estándares para nombrar países, especies u otras clasificaciones y, por lo tanto, pueden tener varias interpretaciones del significado.
Todos los temas y modeladores deben usar los mismos datos de entrada que se han limpiado solo una vez para garantizar que todos usemos las mismas entradas para los modelos. Esto garantiza la reproducibilidad y precisión de los datos en todo el programa.
Datos de salida de modelos
Cuando se producen modelos o estimaciones, producen parámetros y conjuntos de datos que pueden usarse en modelos o estimaciones posteriores. Por lo tanto, los datos de salida de los modelos y estimaciones deben almacenarse en Knowledge Engine junto con los metadatos para garantizar que todos los usuarios puedan comprender cómo se completaron y produjeron los datos, incluido el código del modelo y los conjuntos de datos que se utilizaron para completar estos datos.
Conjuntos de datos intermedios
Los conjuntos de datos intermedios pueden ser datos que se produjeron a través de una etapa de modelación o imputación pero que no se consideran un producto final. Sin embargo, los datos intermedios pueden usarse para otros procesos de modelado y pueden ser importantes para garantizar que los procesos de datos sean reproducibles.
Acceso a datos en Knowledge Engine
Hay dos formas principales de acceder a los datos en Knowledge Engine:
- A través de la interfaz de programación de aplicaciones (API)
- Descarga directa a través de una URL desde un Bucket de Amazon S3
API
¿Qué es una API?
API significa Interfaz de programación de aplicaciones. Es una forma de máquina a máquina de solicitar datos a un servidor, hacer que el servidor recupere e interprete los datos y los devuelva a su máquina. Las API están en todas partes; permiten que las aplicaciones "hablen" entre sí. Por ejemplo, cuando consulta el tiempo en una aplicación meteorológica, la aplicación utiliza una API para capturar los datos y presentarlos de una manera utilizable e interpretable en su teléfono. Las API proporcionan los datos más actualizados sin tener que almacenar datos en su propia máquina.
Para obtener más información sobre las API y cómo usarlas, visite el [Tutorial de API de GBAD] (https://gbadskedoc.org/docs/GBADsAPITutorial).
Los datos de entrada y salida se almacenan en tablas de Amazon RDS. La funcionalidad actual de la API incluye:
- Proporciona acceso a los datos contenidos en las bases de datos públicas.
- Proporciona una lista de todas las tablas contenidas en las bases de datos públicas.
- Para una tabla determinada, proporciona nombres de todos los campos y tipos de datos de esos campos.
Si bien puede haber una curva de aprendizaje para los usuarios humanos de la API, las API son importantes para proporcionar acceso a los datos de máquina a máquina (garantizando la interoperabilidad (intercambio de información) entre sistemas).
La documentación sobre cómo crear llamadas API está disponible en la [Página de documentación del portal de datos de GBAD] (http://gbadske.org/api/dataportal/).
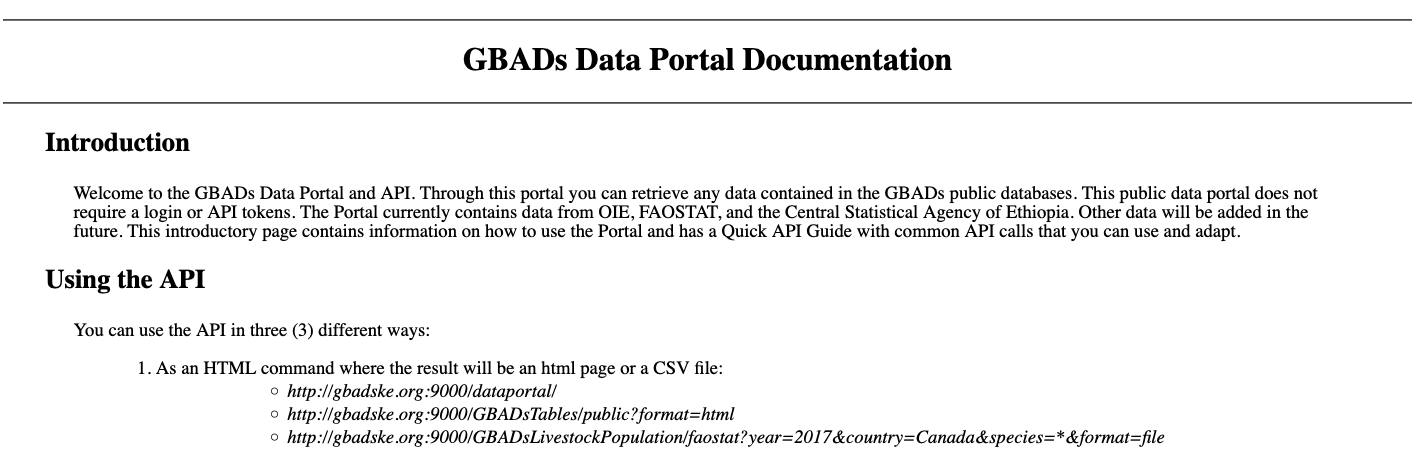
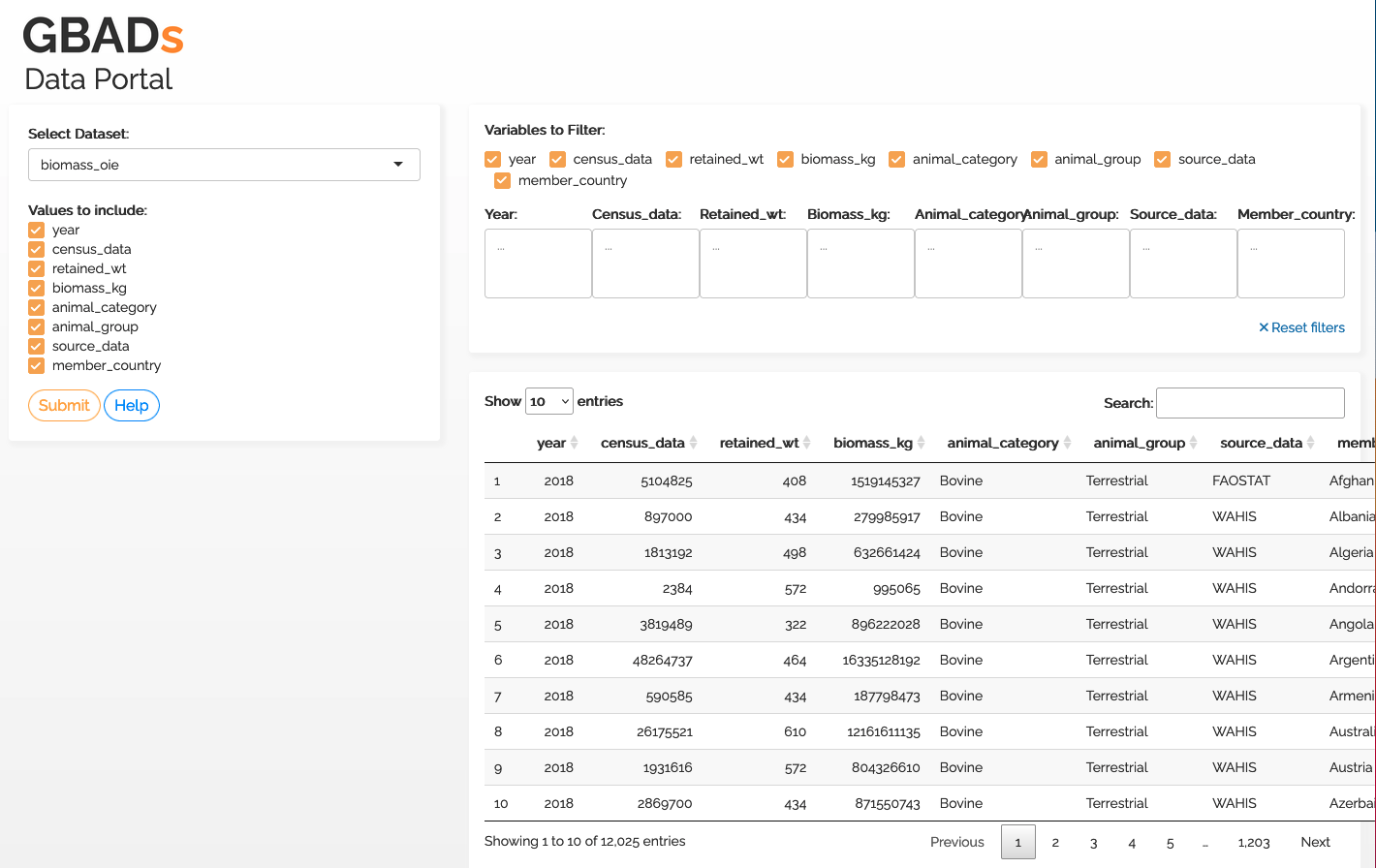
Para mejorar la facilidad de uso para los usuarios humanos, Kurtis Sobkowich creó un panel para ver y descargar datos de la API de GBAD. La URL se vinculará en el Manual cuando el panel se publique en el servidor de GBAD. Por ahora, el panel está disponible en el servidor R shiny de Kurtis: (Interfaz de usuario API de GBADs)[https://kurtissobkowich.shinyapps.io/GBADs_API_UI/]. Espere retrasos: el panel será lento hasta que se entregue en los servidores de GBAD.
También hemos desarrollado un tutorial para usar la API de GBADs en R: Acceder a la API de GBADs en R
Cubos S3
¿Qué es un depósito de Amazon S3?
Un cubo de Amazon Simple Storage Service (S3) es un servicio de almacenamiento de objetos en la nube que le permite almacenar datos y otros objetos digitales. en las nubes.
Los datos de la API también están disponibles a través de depósitos de Amazon S3. Utilizando la URL de S3, los usuarios pueden descargar versiones csv de los datos. Además, almacenaremos archivos utilizados por GBAD que no se pueden almacenar en tablas RDS, como archivos de forma, imágenes, archivos de datos intermedios producidos por modelos, datos de metanálisis y cualquier otro dato que no se pueda estructurar en una tabla RD.
La URL de S3 se utilizará como identificador único de los datos y estará disponible en los metadatos de un conjunto de datos. La URL de S3 se podrá descubrir a través de la API de metadatos de GBAD y, eventualmente, a través de la interfaz de usuario del catálogo de datos (próximamente).
Archivos CSA S3 de Etiopía:
Interfaz del portal de datos GBAD
Búsqueda de datos en Knowledge Engine
Para utilizar los datos en Knowledge Engine, debe poder encontrarlos. La funcionalidad de búsqueda de datos se crea mediante una canalización de metadatos.
Cada tipo de datos tiene metadatos únicos que lo describen. Para obtener más información sobre los metadatos, visite la sección Metadatos del Manual.
La API de metadatos se publicará pronto con información sobre cómo descubrir fuentes de datos almacenadas en GBADs KE basándose en información descriptiva que describe los datos