Zugriff auf Daten in der Knowledge Engine
Ziele:
- Verstehen Sie, wie Sie in der Knowledge Engine auf verschiedene Datentypen zugreifen
- Verstehen Sie, wie Sie nach in der Knowledge Engine gespeicherten Daten suchen
Informationen darüber, was zu tun ist, wenn Sie neue Datensätze identifizieren, die für die Verwendung im GBADs-Programm von Interesse sind, finden Sie im Abschnitt „Datenmitwirkende“ des Data Governance-Handbuchs, in dem Folgendes beschrieben wird:
- Verstehen Sie die Rollen und Verantwortlichkeiten von Personen, die einen neuen Datensatz für die Verwendung des GBADs-Programms identifiziert haben, und wie Sie diese Daten in der Knowledge Engine speichern können
- Verstehen Sie, wie Informatik Daten aus Modellen in der Knowledge Engine speichert
Die Möglichkeiten des Datenzugriffs berücksichtigen die Auffindbarkeit, Zugänglichkeit, Interoperabilität und Wiederverwendbarkeit von Daten sowohl für Menschen als auch für Maschinen.
Datentypen in der Knowledge Engine
Das Datenbenutzerhandbuch bietet GBADs-Mitarbeitern einen Überblick darüber, wie sie auf Daten in der Knowledge Engine zugreifen können. Wir haben 3 Haupttypen von Daten:
- Eingabedaten (oder Rohdaten)
- Daten aus Modellen ausgeben
- Zwischendatensätze
Jeder Datentyp und seine Teilmengen sind einzigartig formatiert und erfordern spezifische Speicheranforderungen, um sicherzustellen, dass die Daten auffindbar, zugänglich, interoperabel und wiederverwendbar (FAIR) sind. Alle Daten müssen mit Metadaten dokumentiert werden, um sicherzustellen, dass die Daten FAIR sind.
Eingabedaten
Eingabe- oder Rohdaten können im GBADs-Programm in zwei Formen vorliegen:
- Datensätze aus Quellen wie der statistischen Datenbank der Ernährungs- und Landwirtschaftsorganisation der Vereinten Nationen (FAOSTAT), der Weltorganisation für Tiergesundheit (WOAH), nationalen Statistikämtern usw.
- Parameter aus Metaanalysen systematischer Übersichtsarbeiten.
- Datensätze, die aus Erhebungsübungen von Experten erstellt wurden.
Diese Daten sind die Eingaben für die Modelle und Berechnungen, die GBADs-Themen erstellen. Eingabedaten können in verschiedenen Formen vorliegen, unterschiedliche Terminologien und Standards für die Benennung von Ländern, Arten oder anderen Klassifizierungen verwenden und daher unterschiedliche Interpretationen der Bedeutung haben.
Alle Themen und Modellierer sollten dieselben Eingabedaten verwenden, die nur einmal bereinigt wurden, um sicherzustellen, dass wir alle dieselben Eingaben für Modelle verwenden. Dies stellt die Reproduzierbarkeit und Genauigkeit der Daten im gesamten Programm sicher.
Daten aus Modellen ausgeben
Wenn Modelle oder Schätzungen erstellt werden, erzeugen sie Parameter und Datensätze, die in nachfolgenden Modellen oder Schätzungen verwendet werden können. Die Ausgabedaten von Modellen und Schätzungen müssen daher zusammen mit Metadaten in der Knowledge Engine gespeichert werden, um sicherzustellen, dass alle Benutzer nachvollziehen können, wie die Daten befüllt und erzeugt wurden, einschließlich des Modellcodes und der Datensätze, die zum Befüllen dieser Daten verwendet wurden.
Zwischendatensätze
Zwischendatensätze können Daten sein, die in einer Phase der Modellierung oder Imputation erstellt wurden, aber nicht als Endprodukt betrachtet werden. Zwischendaten können jedoch für andere Modellierungsprozesse verwendet werden und wichtig sein, um sicherzustellen, dass die Datenprozesse reproduzierbar sind.
Zugriff auf Daten in der Knowledge Engine
Es gibt im Wesentlichen zwei Möglichkeiten, auf die Daten in der Knowledge Engine zuzugreifen:
- Über die Anwendungsprogrammierschnittstelle (API)
- Direkter Download über eine URL aus einem Amazon S3 Bucket
APIs
Was ist eine API?
API steht für Application Programming Interface. Dabei handelt es sich um eine Maschine-zu-Maschine-Methode, bei der Sie einen Server nach Daten fragen, den Server dazu veranlassen, die Daten abzurufen, zu interpretieren und sie an Ihre Maschine zurückzugeben. APIs gibt es überall; Sie ermöglichen es Anwendungen, miteinander zu „sprechen“. Wenn Sie beispielsweise das Wetter in einer Wetter-App überprüfen, verwendet die App eine API, um die Daten abzurufen und sie auf Ihrem Telefon auf nutzbare und interpretierbare Weise darzustellen. APIs stellen die aktuellsten Daten bereit, ohne dass Sie Daten auf Ihrem eigenen Computer speichern müssen.
Weitere Informationen zu APIs und deren Verwendung finden Sie im GBADs API Tutorial.
Eingabe- und Ausgabedaten werden in Amazon RDS-Tabellen gespeichert. Die aktuelle Funktionalität der API umfasst:
- Bietet Zugriff auf Daten in öffentlichen Datenbanken
- Bietet eine Liste aller in den öffentlichen Datenbanken enthaltenen Tabellen
- Stellt für eine bestimmte Tabelle die Namen aller Felder und Datentypen dieser Felder bereit
Auch wenn es für menschliche Benutzer der API möglicherweise eine Lernkurve gibt, sind APIs wichtig für die Bereitstellung von Maschine-zu-Maschine-Zugriff auf Daten (Gewährleistung der Interoperabilität (Informationsaustausch) zwischen Systemen).
Eine Dokumentation zum Erstellen von API-Aufrufen finden Sie auf der GBADs Data Portal Documentation Page.
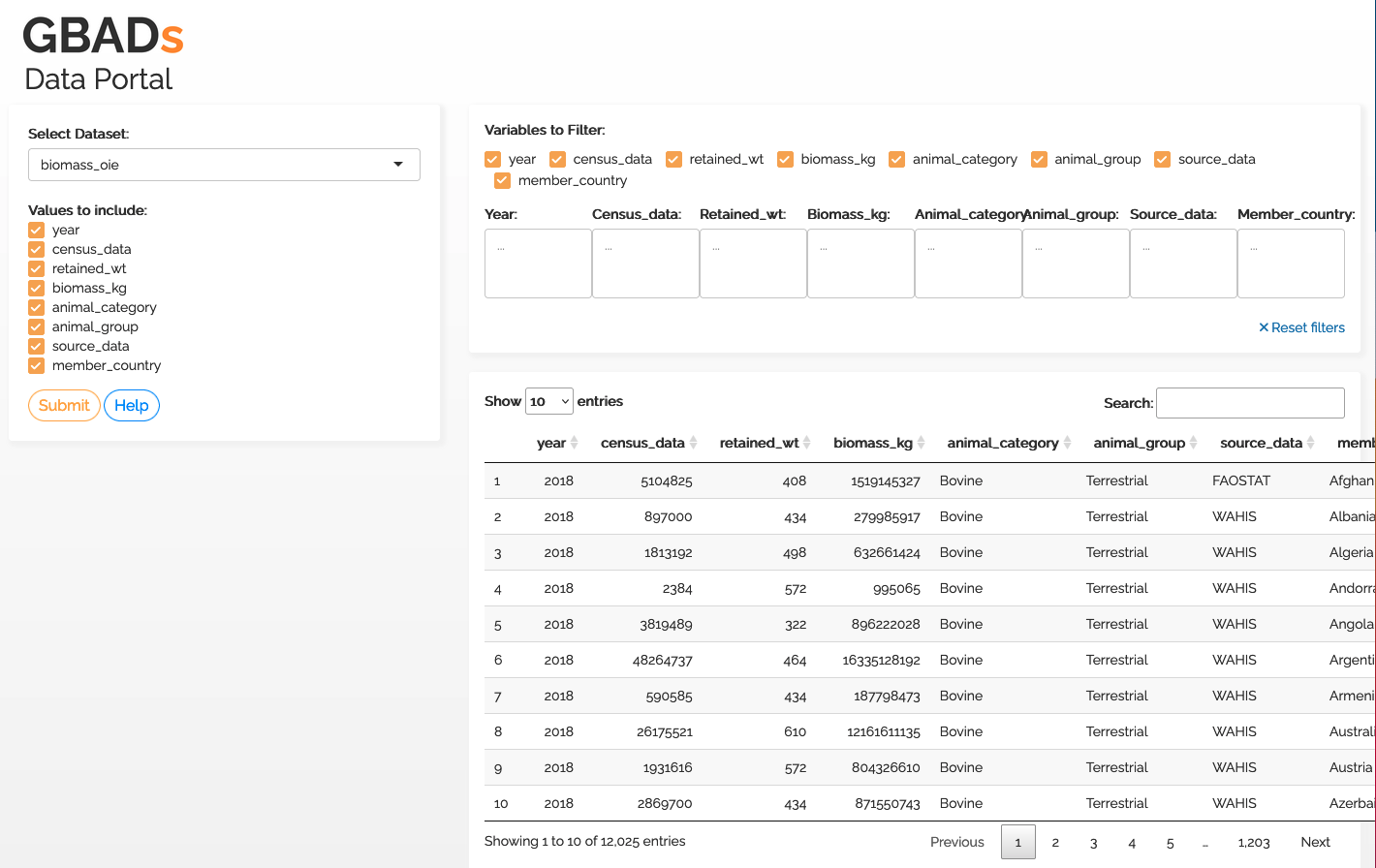
Um die Benutzerfreundlichkeit für menschliche Benutzer zu verbessern, hat Kurtis Sobkowich ein Dashboard erstellt, um Daten von der GBADs-API anzuzeigen und herunterzuladen. Die URL wird im Handbuch verlinkt, wenn das Dashboard auf dem GBADs-Server bereitgestellt wird. Derzeit ist das Dashboard auf dem R-Shiny-Server von Kurtis verfügbar: (GBADs API User Interface)[https://kurtissobkowich.shinyapps.io/GBADs_API_UI/]. Bitte rechnen Sie mit Verzögerungen – das Dashboard wird langsam sein, bis es auf den Servern der GBADs bereitgestellt wird.
Wir haben auch ein Tutorial für die Verwendung der GBADs-API in R entwickelt: Zugriff auf die GBADs-API in R
S3-Buckets
Was ist ein Amazon S3 Bucket?
Ein Amazon Simple Storage Service (S3) Bucket ist ein Cloud-Objektspeicherdienst, der Ihnen die Speicherung von Daten und anderen digitalen Objekten ermöglicht in der Wolke.
Daten aus der API sind auch über Amazon S3 Buckets verfügbar. Über die S3-URL können Benutzer CSV-Versionen der Daten herunterladen. Darüber hinaus speichern wir Dateien, die von GBADs verwendet werden und nicht in RDS-Tabellen gespeichert werden können, wie z. B. Shapefiles, Bilder, von Modellen erstellte Zwischendatendateien, Daten aus Metaanalysen und alle anderen Daten, die nicht in einer RDs-Tabelle strukturiert werden können.
Die S3-URL wird als eindeutige Kennung für die Daten verwendet und ist in den Metadaten eines Datensatzes verfügbar. Die S3-URL wird dann über die GBADs-Metadaten-API und schließlich über die Benutzeroberfläche des Datenkatalogs (in Kürze) erkennbar sein.
Äthiopien CSA S3-Dateien:
GBADs Datenportalschnittstelle
Suche nach Daten in der Knowledge Engine
Um die Daten in der Knowledge Engine nutzen zu können, müssen Sie sie finden können. Die Suchfunktionalität der Daten wird mithilfe einer Metadatenpipeline erstellt.
Jeder Datentyp verfügt über eindeutige Metadaten, die ihn beschreiben. Weitere Informationen zu den Metadaten finden Sie im Abschnitt Metadaten des Handbuchs.
Die Metadaten-API wird in Kürze mit Informationen darüber veröffentlicht, wie im GBADs KE gespeicherte Datenquellen anhand beschreibender Informationen, die Daten beschreiben, ermittelt werden können