Accéder aux données dans le moteur de connaissances
Objectifs:
- Comprendre comment accéder à différents types de données dans le Knowledge Engine
- Comprendre comment rechercher des données stockées dans le Knowledge Engine
Pour plus d'informations sur la marche à suivre lorsque vous identifiez de nouveaux ensembles de données intéressants à utiliser dans le programme GBADs, visitez la section Contributeur de données du Manuel de gouvernance des données qui décrit les éléments suivants :
- Comprendre les rôles et les responsabilités des personnes qui ont identifié un nouvel ensemble de données pour l'utilisation du programme GBADs, et comment stocker ces données dans le moteur de connaissances.
- Comprendre comment l'informatique stocke les données des modèles dans le moteur de connaissances
Les moyens d'accéder aux données prennent en compte la possibilité de trouver, l'accessibilité, l'interopérabilité et la réutilisation des données pour les humains et les machines.
Types de données dans le moteur de connaissances
Le guide de l'utilisateur des données fournit aux collaborateurs du GBAD un aperçu de la manière d'accéder aux données dans le moteur de connaissances. Nous disposons de 3 grands types de données :
- Données d'entrée (ou données brutes)
- Données de sortie des modèles
- Ensembles de données intermédiaires
Chaque type de données et leurs sous-ensembles sont formatés de manière unique et nécessitent des exigences de stockage spécifiques pour garantir que les données peuvent être trouvées, accessibles, interopérables et réutilisables (FAIR) ; toutes les données doivent être documentées avec des métadonnées pour garantir qu'elles sont JUSTE.
Des données d'entrée
Les données d'entrée ou les données brutes peuvent se présenter sous deux formes dans le programme GBADs :
- Ensembles de données provenant de sources telles que la base de données statistiques de l'Organisation des Nations Unies pour l'alimentation et l'agriculture (FAOSTAT), l'Organisation mondiale de la santé animale (WOAH), les agences nationales de statistiques, etc.
- Paramètres obtenus à partir de méta-analyses issues de revues systématiques.
- Ensembles de données produits à partir d'exercices de sollicitation d'experts.
Ces données sont les entrées dans les modèles et les calculs produits par les thèmes GBAD. Les données d'entrée peuvent se présenter sous différentes formes, utiliser différentes terminologies et normes pour nommer les pays, les espèces ou d'autres classifications, et peuvent donc avoir diverses interprétations de leur signification.
Tous les thèmes et modélisateurs doivent utiliser les mêmes données d'entrée qui ont été nettoyées une seule fois pour garantir que nous utilisons tous les mêmes entrées dans les modèles. Cela garantit la reproductibilité et l’exactitude des données dans l’ensemble du programme.
Données de sortie des modèles
Lorsque des modèles ou des estimations sont produits, ils produisent des paramètres et des ensembles de données qui peuvent être utilisés dans des modèles ou des estimations ultérieurs. Les données de sortie des modèles et des estimations doivent donc être stockées dans le moteur de connaissances avec les métadonnées pour garantir que tous les utilisateurs puissent comprendre comment les données ont été alimentées et produites, y compris le code du modèle et les ensembles de données utilisés pour alimenter ces données.
Ensembles de données intermédiaires
Les ensembles de données intermédiaires peuvent être des données produites au cours d’une étape de modélisation ou d’imputation, mais qui ne sont pas considérées comme un produit final. Les données intermédiaires peuvent toutefois être utilisées pour d’autres processus de modélisation et peuvent être importantes pour garantir la reproductible des processus de données.
Accéder aux données dans le Knowledge Engine
Il existe deux manières principales d'accéder aux données dans le Knowledge Engine :
- Via l'interface de programmation d'applications (API)
- Téléchargement direct via une URL à partir d'un compartiment Amazon S3
API
Qu'est-ce qu'une API ?
API signifie Application Programming Interface. Il s'agit d'un moyen machine à machine de demander des données à un serveur, de demander au serveur de récupérer et d'interpréter les données et de les renvoyer à votre machine. Les API sont partout ; ils permettent aux applications de « communiquer » entre elles. Par exemple, lorsque vous consultez la météo sur une application météo, celle-ci utilise une API pour récupérer les données et les présenter de manière utilisable et interprétable sur votre téléphone. Les API fournissent les données les plus récentes sans avoir à stocker les données sur votre propre ordinateur.
Pour plus d'informations sur les API et comment les utiliser, visitez le Tutoriel API GBADs.
Les données d'entrée et de sortie sont stockées dans des tables Amazon RDS. Les fonctionnalités actuelles de l'API incluent :
- Donne accès aux données contenues dans les bases de données publiques
- Fournit une liste de toutes les tables contenues dans les bases de données publiques
- Pour une table donnée, fournit les noms de tous les champs et les types de données de ces champs
Bien qu'il puisse y avoir une courbe d'apprentissage pour les utilisateurs humains de l'API, les API sont importantes pour fournir un accès de machine à machine aux données (garantir l'interopérabilité (échange d'informations) entre les systèmes).
La documentation sur la façon de créer des appels d'API est disponible sur la Page de documentation du portail de données GBADs.
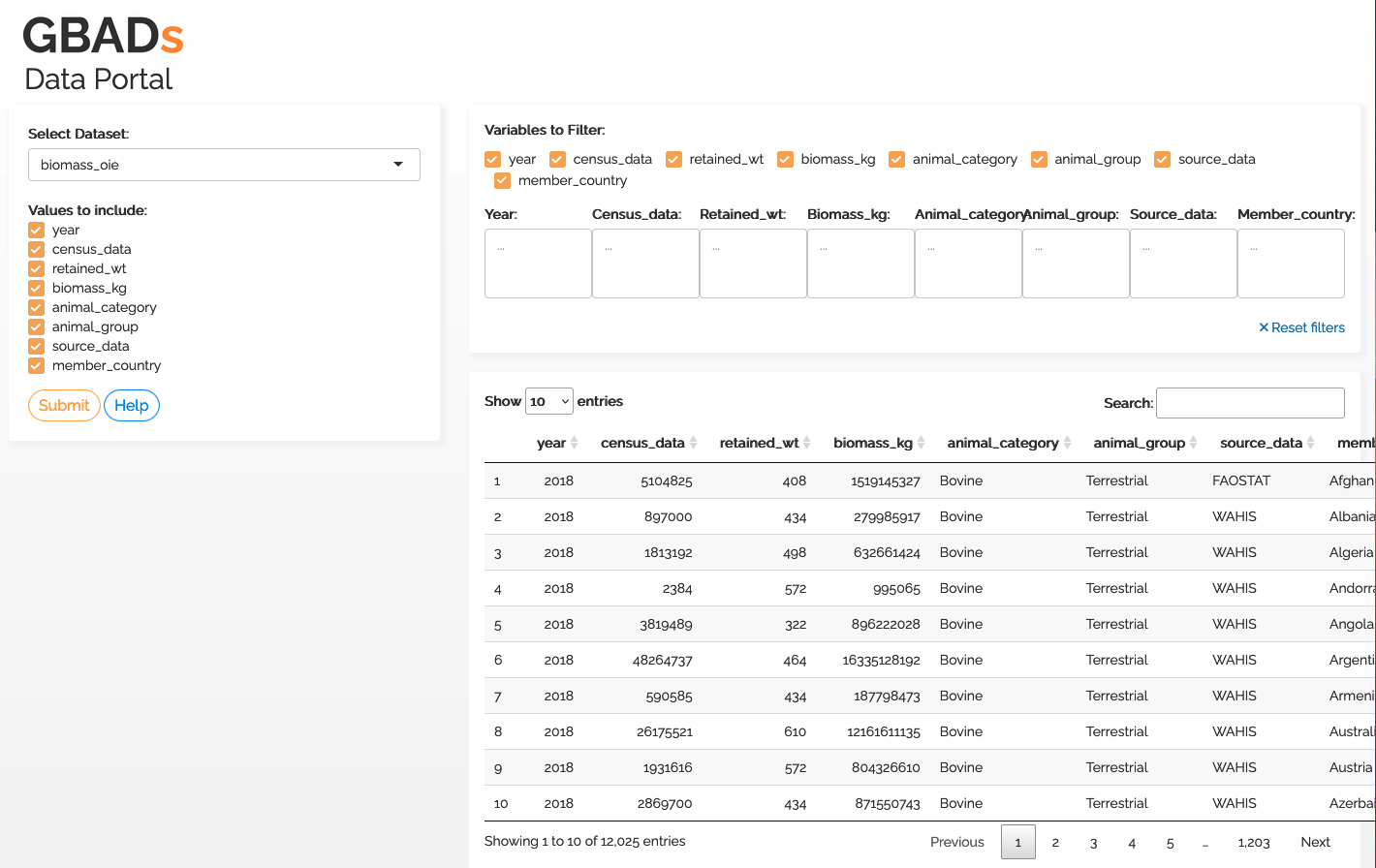
Pour améliorer la facilité d'utilisation pour les utilisateurs humains, Kurtis Sobkowich a créé un tableau de bord pour afficher et télécharger les données de l'API GBADs. L'URL sera liée dans le manuel lorsque le tableau de bord sera servi sur le serveur GBADs. Pour l'instant, le tableau de bord est disponible sur le serveur R Shiny de Kurtis : (interface utilisateur de l'API GBADs)[https://kurtissobkowich.shinyapps.io/GBADs_API_UI/]. Veuillez vous attendre à des retards : le tableau de bord sera lent jusqu'à ce qu'il soit servi sur les serveurs des GBAD.
Nous avons également développé un tutoriel pour utiliser l'API GBADs dans R : Accès à l'API GBADs dans R
Compartiments S3
Qu'est-ce qu'un compartiment Amazon S3 ?
Un compartiment Amazon Simple Storage Service (S3) est un service de stockage d'objets cloud qui vous permet de stocker des données et d'autres objets numériques. dans le nuage.
Les données de l'API sont également disponibles via les compartiments Amazon S3. À l'aide de l'URL S3, les utilisateurs peuvent télécharger des versions CSV des données. De plus, nous stockerons les fichiers utilisés par les GBAD qui ne peuvent pas être stockés dans des tables RDS tels que les shapefiles, les images, les fichiers de données intermédiaires produits par les modèles, les données issues de méta-analyses et toute autre donnée qui ne peut pas être structurée dans une table RD.
L'URL S3 sera utilisée comme identifiant unique pour les données et sera disponible dans les métadonnées d'un ensemble de données. L'URL S3 sera alors détectable via l'API de métadonnées GBADs, et éventuellement l'interface utilisateur du catalogue de données (à venir).
Fichiers CSA S3 d’Éthiopie :
Interface du portail de données GBADs
Recherche de données dans le Knowledge Engine
Pour utiliser les données dans le Knowledge Engine, vous devez pouvoir les trouver. La fonctionnalité de recherche des données est construite à l'aide d'un pipeline de métadonnées.
Chaque type de données possède des métadonnées uniques qui le décrivent. Pour plus d'informations sur les métadonnées, veuillez visiter la section Metadata du manuel.
L'API de métadonnées sera bientôt publiée avec des informations sur la façon de découvrir les sources de données stockées dans les GBADs KE sur la base d'informations descriptives décrivant les données